Rumal, a web GUI for Thug
22 Feb 2016 Pietro Delsante gsoc rumal thug
As you may know, Thug is a handy tool for studying exploit kits, as it emulates a real browser complete of a set of plugins like Adobe Reader, Flash and Java. When you feed Thug with the URL of a suspicious web page, it “crawls” it and starts fetching and executing any internal or external JavaScript, following redirects and downloading files just like a browser would do. When Thug encounters some files it cannot analyze by itself (like Flash, Java and PDF), it passes them to external tools. Thug’s results are then collected in a variety of formats, with the default one being a set of collections inside a MongoDB database. Thug works very well but the output can be challenging to navigate, the result often being the ability to only check if the exploit kit’s payload (e.g. an *.exe file) has been downloaded: if not, one may think that the URL is not malicious, or maybe that the exploit kit is dead. That’s where a web GUI would come handy, and that’s exactly what Thug’s Rumal was born for: there’s plenty of information that can be extracted from Thug’s output and that can help a correct analysis to determine the maliciousness of a web page.
Rumal was developed by Tarun Kumar during the Google Summer of Code 2015 program, and its goal is to provide a web GUI for Thug. Rumal’s architecture includes a front-end and a back-end: front-end module currently includes two stand-alone daemons and a web server. The latter provides the GUI for Rumal, letting you submit new URLs and browsing results, and it uses two different databases: MongoDB for Thug’s results and metadata, and a relational database for everything that uses Django’s ORM (e.g. users, groups, etc). Analysis tasks also make use of Django’s ORM, and the MongoDB collections are only used to store the final results.
So, once you submit a new URL for analysis, the front-end creates a new Task object, assigning it the initial status value. The front-end daemon (fdaemon) periodically checks the database for new tasks and submits them to the back-end using a set of REST APIs; then, it starts polling the back-end’s APIs for the analysis results. When the analysis is complete, results are retrieved and stored to the local MongoDB database, along with any files downloaded during the analysis, and a full packet capture (pcap) of the network traffic generated by Thug. The task’s status is then updated and marked as retrieved (or failed).
At this point, the third daemon (enrich) takes Thug’s results from Mongo and enriches them with metadata provided by a set of specific plugins: for example, one takes all IP addresses seen during an analysis and performs a WHOIS query on them, while another plugin performs a GeoIP lookup. A third plugin runs the PCAP through an external service (PCAPOptikon) that analyzes it with Suricata IDS.
The back-end module is pretty simple. The web server hosts a set of REST APIs that let the front-end programmatically submit tasks and retrieve results. MongoDB is used by Thug to store its results, while the relational database is used by Django to store tasks, API users and keys, and so on. The back-end daemon (run_thug) reads tasks from Django’s ORM and executes them by launching Thug inside a Docker container. Thug will use the back-end’s MongoDB instance (that is outside of the container) to store its results. Once the analysis is over, the container is destroyed to avoid conflicts that would arise from the reuse of Thug’s global Logger instance. The results and files are then transferred to the front-end when fdaemon requests them through the API.
To be able to test Rumal, you will need to configure both the back-end and front-end environments. They can live on the same host, or on two separate hosts: that’s entirely up to you. You can find the latest version of Rumal on GitHub, along with installation instructions.
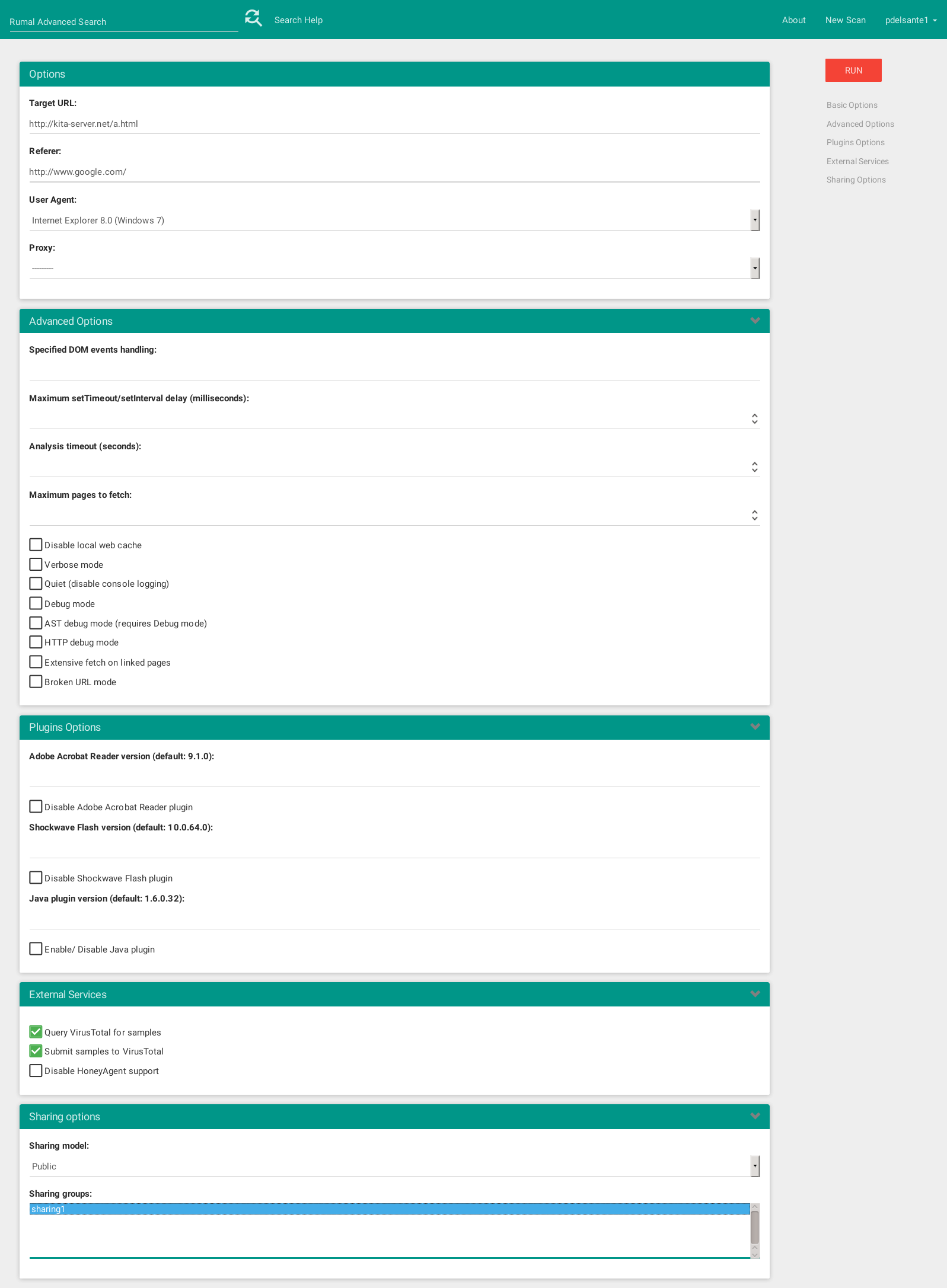
Submitting a new analysis task is as easy as logging in and typing a new URL in the box, as shown in the image below. You can also expand the various boxes to access some advanced options that should be familiar to you if you are a Thug user. You will also find a box that lets you decide whether you want to share your analysis with other users or groups: this may be especially useful in multi-user environments.
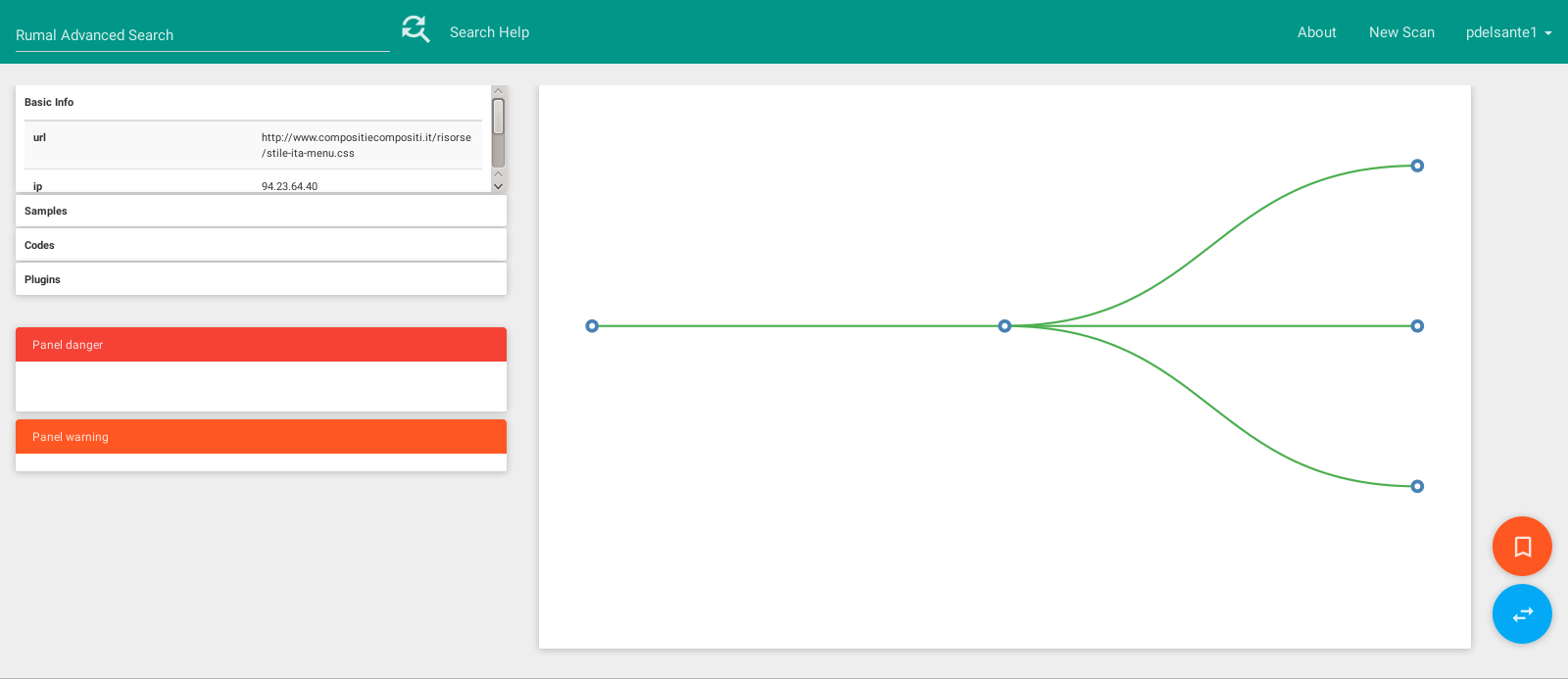
Once the analysis is finished, Rumal will show you a tree graph with all the web resources that were involved in the current analysis. Clicking a node in the graph will expand or collapse it, while double clicking it will select it. The boxes on the left side will contain details about the currently selected node.
Rumal is a very promising project, but it’s still in an early alpha stage. We welcome feedback and contributors, get in touch at pietro[dot]delsante[at]gmail[dot]com!
Future developments:
- Existing code cleanup
- Consolidate back and front end results into MongoDB, front-end could also switch to Elastic Search, now fully supported by Thug
- Remove requirement of a fully functional Thug install running in the front-end
- the JavaScript part does need some rethinking and it should also be made more robust (e.g. it should not die for unexpected or missing values in structures)
- Improve data visualization of analysis results
- Move configuration options to external config files
- Parallelize the enrich daemon
- Threads should be replaced by processes whenever possible
- Introduce a message queue for internal communication to improve performance