Honeybrid testing
07 Aug 2009 Robin Berthier honeybrid-gsoc-testing
Second milestone reached! Honeybrid has now all its functionalities working and it’s time for testing. In order to check that everything works efficiently, I deployed a Windows honeypot to receive traffic from five /24 unused subnets during half an hour. Here are the details of this experiment.
Configuration
Here is a overall diagram of the testing architecture:
(Internet) <=====> [NATing Gateway with Honeybrid] <-------> [Windows Honeypot]
The NATing gateway was configured with the following iptables rules:
iptables -A PREROUTING -d -j DNAT --to-destination
Honeybrid works by listening for packets on the netfilter queue, so the following two rules were added:
iptables -I FORWARD -s -j QUEUE -m comment --comment "Honeybrid testing" iptables -I FORWARD -s -j QUEUE -m comment --comment "Honeybrid testing"
Finally, Honeybrid was configured with the following rules:
module "hash" { function = hash; backup = /etc/honeybrid/hash.tb; } target { filter "dst host "; frontend "hash"; }
The first section of this rule file defines a module named “hash” that uses the hash function to compute payload checksum and accept packets that carries unknown checksum. Results for this module are stored in the file “/etc/honeybrid/hash.tb”
The second section of this rule file defines a target for our windows Honeypot. The PCAP filter allows Honeybrid to detect packets covered by this rule and the frontend parameter tells Honeybrid which module to use to accept or reject packets.
Results
During the 30 minutes of the test, Honeybrid processed 11,500 flows, consisting mainly of one brute force attack targeting port tcp/1433 (Microsoft SQL). The hash module accepted 11,233 flows, rejected 105 flows and could not decide for 162 flows. Accepted flows are the ones made of packets with unknown payload. Rejected flows have packets with known payloads. Finally flows for which the hash module could not decide are the ones having packets with no payload.
Here is the top 5 ports targeted:
-
- tcp/1433: 11,125 flows
-
- tcp/3268: 3,268 flows
-
- udp/2176: 18 flows
-
- udp/15947: 17 flows
-
- tcp/80: 12 flows
Honeybrid sustained an average rate of 350 flows per minute, as shown on the graph below:
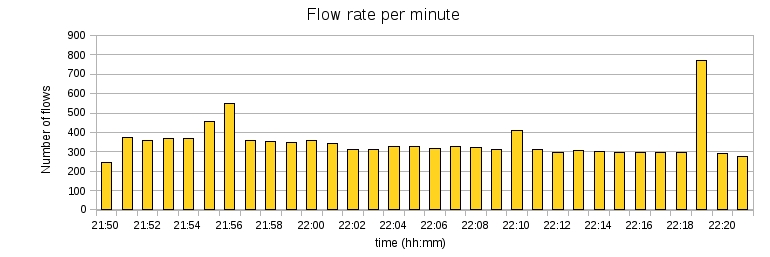
I was interested in measuring the time taken by Honeybrid to process individual packets, because it directly impacts the scalability of the application. On average, the hash module of Honeybrid took 35ms to decide on the fate of each packet, which is a pretty high value, because it means no more than 29 packets can be handled per second. To better understand where the delay came from, I divided the hash module processing time in two: 1) a first duration for the hash computation and lookup, and 2) a second duration for the time to save the results to an external file. The next two graphs show these two duration respectively:
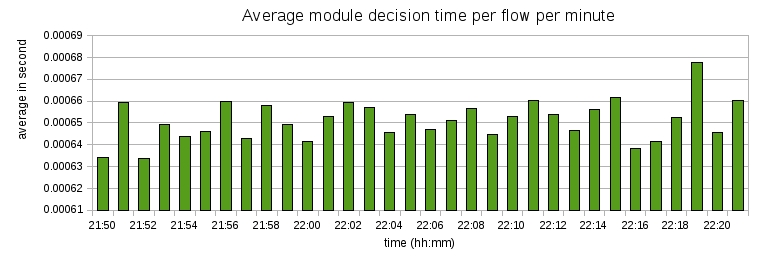
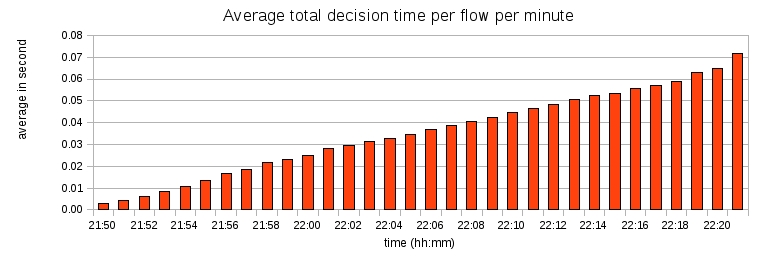
As we can see, saving results to file consumed most of the total processing time, and kept increasing with Honeybrid recording more new payload checksums. Without this time consuming task, the hash module took on average 0.6 ms to process packets, which means Honeybrid can currently handle a maximum of 1,500 packets per second (the code is not yet optimized and has been compiled with the debug flag, so I think this maximum traffic rate can be increased further).
As a result, I have to work on the file saving functionality which is the main bottleneck for performance. I think the solution will be to save to an external file every minute instead of after every packet.
Next steps
Here are the next tasks to reach the third and final milestone:
-
- Improve module file saving functionality
-
- Test and debug the replay process
-
- Implement a module based on Snort
-
- Add support for TCP options when replaying packets
-
- Add support for NATing within Honeybrid